
Ogromny postęp, który dokonał się w genetyce i biologii molekularnej na przestrzeni ostatnich kilkudziesięciu lat zmienił bardzo dużo w sposobie, w jaki uprawiane są te dziedziny. Jedno się jednak nie zmieniło. Badanie sekwencji i struktury kwasów nukleinowych i białek nadal pozostaje kwestią absolutnie kluczową i punktem wyjścia dla ogromnej części projektów naukowych. Zapoznanie się z podstawowymi mechanizmami działania tych cząsteczek jest niezbędne, aby zrozumieć bieżące doniesienia z wymienionych wyżej dyscyplin. Dla części czytelników wymienione niżej informacje mogą być oczywiste. Te osoby mogą z czystym sumieniem pominąć “słowniczek” i od razu przejść do dalszej części tekstu. Bez dłuższego ociągania się, wprowadźmy najważniejsze pojęcia:
Kwasy nukleinowe, takie jak DNA (kwas deoksyrybonukleinowy) i RNA (kwas rybonukleinowy), są liniowymi polimerami[1], składającymi się z monomerów nazywanych nukleotydami. Każdy naturalny nukleotyd posiada trzy części: pierścień cukrowy złożony z pięciu atomów, grupę fosforanową oraz zasadę azotową. Jeżeli cukier jest deoksyrybozą, to polimerem jest RNA. Jeżeli natomiast cukier jest rybozą, to polimerem jest RNA.
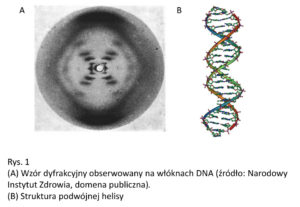
DNA – kwas deoksyrybonukleinowy. Stanowi najpowszechniejszy nośnik informacji genetycznej. Przeważnie tworzy strukturę podwójnej helisy(Rys. 1). Dwie nici DNA są ułożone antyrównolegle. Oznacza to, że sekwencję drugiej nici w obrębie helisy odczytujemy w odwrotnym kierunku niż pierwszej. Każda nić posiada liniową sekwencję czterech zasad azotowych: adenin (A), cytozyn (C), guanin (G) i tymin (T). Nici są względem siebie komplementarne, czyli dopasowane. T w jednej nici oddziałuje z A w drugiej, a C oddziałuje z G. Dzięki temu, w oparciu o sekwencję jednej nici można odtworzyć nić komplementarną. Na tej zasadzie działa zarówno replikacja DNA jak i transkrypcja (przepisywanie DNA na RNA) [1,3].
RNA – kwas rybonukleinowy. Jest m.in. pośrednikiem w przekazie informacji pomiędzy DNA i białkiem. W takim przypadku mówimy o mRNA (od ang. messenger RNA – RNA informacyjne, matrycowe). U niektórych wirusów stanowi też nośnik informacji genetycznej (zamiast DNA). Może przyjmować różne struktury i formy, ale mRNA, będące matrycą do syntezy białek, jest jednoniciowe. W sekwencji RNA zamiast tyminy występuje uracyl (U). RNA może być nie tylko nośnikiem informacji, ale pełnić też funkcje strukturalne (tworząc złożone “rusztowania” dla białek) i enzymatyczne. Małe cząsteczki RNA (tRNA – RNA transportowe) odgrywają też kluczową rolę w syntezie białek, dostarczając odpowiednie aminokwasy do rybosomu. Sam rybosom, swoista “fabryka” molekularna odpowiedzialna za produkcję białek, jest kompleksem, w którego skład wchodzą zarówno białka, jak i cząsteczki RNA. Ze względu na mnogość pełnionych przez RNA funkcji postuluje się, że na wczesnym etapie ewolucji samoreplikujące się cząsteczki RNA (lub innego polimeru o zbliżonych właściwościach) mogły powielać się i podlegać doborowi naturalnemu bez udziału DNA i białek[2].
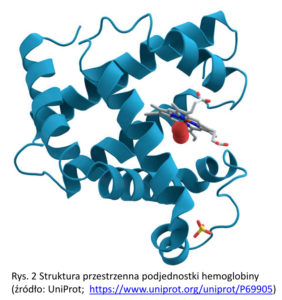
Białka to duże biocząsteczki składające się z linowego łańcucha aminokwasowego. Tworzy go 20 podstawowych aminokwasów białkowych. Białko jest syntetyzowane na matrycy mRNA. Trzy nukleotydy DNA/RNA odpowiadają pojedynczemu aminokwasowi. Większość białek składa się z kilkuset aminokwasów. Liniowy łańcuch aminokwasowy zwija w złożoną trójwymiarową strukturę (Rys. 2). Białka mogą oddziaływać ze sobą nawzajem (tworząc jeszcze większe kompleksy, zawierające od kilku do kilkudziesięciu białek), z DNA, RNA oraz z błoną komórkową i wieloma mniejszymi cząsteczkami docelowymi. Pełnią funkcje enzymatyczne, regulacyjne i strukturalne. Forma przestrzenna przyjmowana przez białko jest w głównej mierze warunkowana sekwencją aminokwasową. Może ona jednak ulegać zmianie pod wpływem modyfikacji chemicznych oraz oddziaływania z innymi biocząsteczkami. Ta swoista elastyczność stanowi jeden z kluczowych mechanizmów regulacji procesów biologicznych [2].
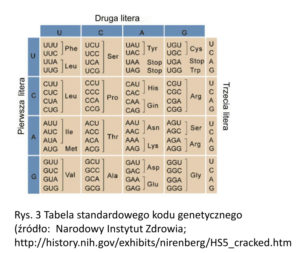
Uniwersalny kod genetyczny– sposób w jaki trójki nukleotydów (kodony) w DNA/RNA przepisywane są na aminokwasy w łańcuchu białkowym (Rys. 3).Większość organizmów posługuje się takim samym kodem, co znacząco ułatwia życie osobom parającym się inżynierią genetyczną. Uniwersalność kodu umożliwia m.in. produkcję białek o zastosowaniach medycznych i przemysłowych w mikroorganizmach. Niemniej jednak warto pamiętać, że biologia jest nauką o wyjątkach od reguł i nie brakuje organizmów, w których mają miejsce odstępstwa od kodu uniwersalnego. Nawet w obrębie komórek kręgowców (w tym ludzkich), mitochondria syntetyzują białka z pewnymi odstępstwami od kodu uniwersalnego. Trójka nukleotydowa, która w kodzie uniwersalnym sygnalizuje koniec białka, w mitochodriach kręgowców koduje aminokwas tryptofan, a jeden z kodonów przeważnie odpowiadający izoleucynie koduje metioninę[4]. Stosunkowo nową i niezwykle ciekawą dziedziną badań jest modyfikowanie komórkowej maszynerii translacyjnej tak, aby rozszerzyć kod genetyczny, umożliwiający syntetyzowanie białek zawierających niewystępujące w naturze aminokwasy [5].
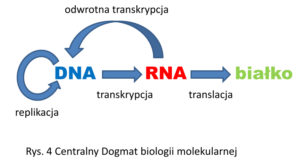
Tyle suchych informacji. Jak przekłada się to na działanie układów żywych? Tutaj należy wprowadzić pojęcie Centralnego Dogmatu biologii molekularnej. Opisuje on przepływ informacji genetycznej pomiędzy biocząsteczkami. Informacja genetyczna zawarta w DNA może ulegać powielaniu (replikacji), a także przepisywaniu na RNA w procesie transkrypcji. RNA może posłużyć jako matryca do syntezy białka (translacja) lub ulec ponownemu przepisaniu na DNA na drodze odwrotnej transkrypcji (Rys. 4). Z tego ostatniego procesu korzystają niektóre z wirusów, u których nośnikiem informacji genetycznej jest RNA. Sekwencja aminokwasowa białka nie może natomiast zostać ponownie przepisana na sekwencję nukleotydową RNA lub DNA. To co nie zachodzi w przyrodzie można jednak zrobić “sztucznie”. Znając sekwencję danego białka oraz uniwersalny kod genetyczny, można zaprojektować, a następnie zsyntetyzować łańcuch DNA, który owe białko będzie kodował. Podajmy przykład. Przyjmijmy, że poznaliśmy sekwencję aminokwasową białka, a nie znamy sekwencji genomowej organizmu, z którego pochodzi lub też wiemy, że ów organizm posługuje się alternatywnym kodem genetycznym. Wykorzystując proste narzędzie bioinformatyczne, możemy “na sucho” przepisać aminokwasy na trójki nukleotydowe według standardowego kodu genetycznego. Tak uzyskaną sekwencję przesyłamy następnie firmie zajmującej się syntezą genów. Otrzymany łańcuch DNA możemy wprowadzić np. do komórki bakteryjnej, która naprodukuje w dużej ilości białko identyczne z tym, które pierwotnie zidentyfikowaliśmy, umożliwiając nam badanie jego właściwości w warunkach laboratoryjnych.
Współczesna biologia molekularna dysponuje szerokim wachlarzem metod umożliwiających badanie sekwencji i struktury kwasów nukleinowych oraz manipulowanie nimi [1, 3]. Już od lat 70-tych dostępne są enzymy restrykcyjne, pełniące funkcję “nożyczek” umożliwiających wycinanie i przenoszenie genów pomiędzy organizmami. W tej samej dekadzie opracowano też stosowaną po dzień dzisiejszy technikę sekwencjonowania DNA. W latach 80-tych natomiast wprowadzono technikę PCR (PolymeraseChain Reaction – Łańcuchowa Reakcja Polimerazy), umożliwiającą szybkie namnożenie wybranego odcinka DNA [6]. Kamienie milowe w rozwoju biologii molekularnej można dla porządku przedstawić na osi czasu(Rys. 5) [7]:
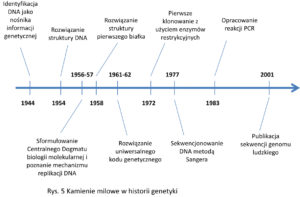
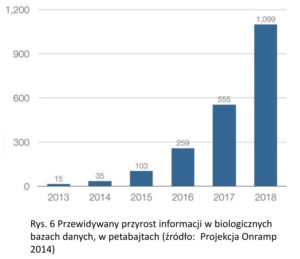
Każda z wyżej wymienionych technik przeszła daleko idącą ewolucję, która wykracza jednak poza obszar niniejszego tekstu. Warto jednak nadmienić zwłaszcza o ogromnym wzroście przepustowości i spadku kosztów dotyczących badania sekwencji biocząsteczek. Stosowane współcześnie techniki sekwencjonowania DNA, RNA i białek nieustannie generują ogromne ilości danych, sięgające już setek petabajtów rocznie (jeden petabajt to tysiąc terabajtów) (Rys. 6). Tworzy to paradoksalną sytuację, gdy dylematem staje się nadmiar dostępnych informacji, oraz to jak je analizować (oraz przechowywać i udostępniać). Jest to prawdopodobnie jedno z głównych wyzwań dla biologii w XXI wieku [8].
[1] “Molecular Biology Of The Gene”; 7Th Edition,2017 James D. Watson
[2] “Biochemia”; Jeremy M. Berg, John L. Tymoczko, Lubert Stryer, wydanie czwarte, 2009, PWN
[3] “DNA. Historia rewolucji genetycznej”; Watson James D., Berry Andrew, Davies Kevin, 2018, CiS
[4] DNA Interactive: http://www.dnai.org/a/index.html[2]
[5] Wang, Qian et al. “Expanding the genetic code for biological studies.” Chemistry & biology vol. 16,3 (2009): 323-36. doi:10.1016/j.chembiol.2009.03.001
[6] DNA Interactive: http://www.dnai.org/b/index.html
[7] DNA Interactive: http://www.dnai.org/timeline/index.html
[8] Papageorgiou, Louis et al. “Genomic big data hitting the storage bottleneck.” EMBnet.journal vol. 24 (2018): e910.
- polimer – cząsteczka chemiczna składająca się z wielokrotnie powtórzonych jednostek (można myśleć o nich jak o “cegiełkach”), zwanych monomerami. Polimerami są m.in. białka i kwasy nukleinowe, a także liczne tworzywa sztuczne. ↑
- Strona DNA Ineractive wymaga działającej wtyczki Flash ↑




